Лекции по учебной дисциплине "Базы данных" содержат основные понятия и определения, материал полностью раскрывает содержание данного курса. В лекциях содержатся так же иллюстративный материал в виду блок-схем с подробным описанием. Каждая тема содержит рекомендуемый список литературы.
Создайте Ваш сайт учителя Видеоуроки Олимпиады Вебинары для учителей
Лекции по учебной дисциплине "Базы данных"
Вы уже знаете о суперспособностях современного учителя?

Тратить минимум сил на подготовку и проведение уроков.

Быстро и объективно проверять знания учащихся.

Сделать изучение нового материала максимально понятным.

Избавить себя от подбора заданий и их проверки после уроков.

Наладить дисциплину на своих уроках.

Получить возможность работать творчески.
Просмотр содержимого документа
«Лекции по учебной дисциплине "Базы данных" »
Тема 1. Введение в предмет, основные понятия и термины.
Основные понятия.
Исходное представление о базах данных массового пользователя будет, скорее всего, построено на аналогии: база данных - база, склад, хранилище, что близко к действительности. Проводя дальнейшую аналогию, можно сказать, что база данных – это хранилище, где принимают взаимосвязанные данные, сортируют по темам и хранят в некотором порядке в одном месте, а также частично перерабатывают. Эти данные выдают строго по назначению и по требованию, оформленному согласно определенным правилам. Потребителю не обязательно знать, в каком виде хранятся данные, при этом он решает какие данные, в каком количестве и в какой форме ему их нужно выдать. Это образное и, в общем, верное представление.
Основные идеи современных информационных технологий опираются на концепцию баз данных. Следовательно, базовым элементом информационных технологий являются данные.
В основе концепции лежит механизм предоставления обрабатывающей программе из всех хранимых данных только тех, которые ей необходимы, и в форме, требуемой именно этой программе. Сама же форма описывается на логическом уровне, т.е. уровне, видимом из программы.
Одним из важнейших понятий в теории баз данных является понятие информации. Информация – это любые сведения о каком-либо событии, процессе, объекте. Другими словами, это все, что может интересовать пользователя.
Данные – это информация, представленная в определенном виде. Для компьютерных технологий данные представлены в дискретном, фиксированном виде, удобном для хранения и обработки на компьютере, а также для передачи по каналам связи.
Таким образом, база данных – это именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Характерной чертой баз данных является постоянство:
данные постоянно накапливаются и используются;
состав и структура данных, необходимых для решения тех или иных прикладных задач, обычно постоянны во времени;
отдельные или все элементы данных могут меняться, что является признаком постоянной актуальности.
Т.е. речь идет о признаке персистентности (устойчивости) данных в базе данных.
Таким образом, можно привести более точное определение базы данных, а именно, база данных – это совокупность взаимосвязанных устойчивых данных при наличии такой минимальной избыточности, которая допускает их независимое использование оптимальным образом для одного или нескольких приложений в определенной предметной области. БД состоит из множества связанных файлов, причем связи (отношения) между ними хранятся вместе данными.
Поскольку одни и те же данные могут использоваться для решения многих задач, то и приложений (программ) к одной и той же базе данных может быть много. Все приложения, работающие с одной и той же базой данных, должны функционировать корректно, не мешать друг другу и учитывать все изменения, которые вносятся другими приложениями. Работу всех приложений координирует СУБД.
Система управления базами данных (СУБД) – это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования баз данных многими пользователями.
Примеры СУБД: MS SQL, MS Access, Oracle.
Классификация БД.
По технологии обработки данных базы данных подразделяются на распределенные и централизованные.
Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, которые хранятся в различных компьютерах одной вычислительной сети. Т.е. это набор логически связанных между собой совокупностей разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети. Работа с такой базой осуществляется с помощью распределенной системы управления базой данных.
Распределенная СУБД – это программный комплекс, предназначенный для управления распределенными базами данных и обеспечивающий прозрачный доступ пользователей к распределенной информации.
Из определения следует, что СУБД должна сделать распределение данных прозрачным (незаметным) для конечного пользователя. Другими словами, от пользователей должен быть полностью скрыт тот факт, что распределенная база данных состоит из нескольких фрагментов, которые могут размещаться на различных компьютерах. Цель обеспечения прозрачности состоит в том, чтобы распределенная система внешне выглядела как централизованная. Это требование называют основным принципом создания распределенных СУБД.
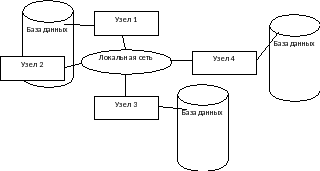
Рис. 1. Топология распределенной СУБД
Централизованная база данных хранится в памяти одной вычислительной системы. Доступ к данным в этом случае обеспечивается для любого пользователя по сети. СУБД просто поддерживает распределенную обработку, но не может рассматриваться как распределенная СУБД.
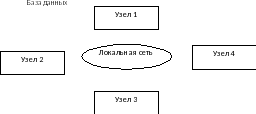
Рис. 2. Топология системы с распределенной обработкой данных
По способу доступа базы данных подразделяются на базы данных с локальным доступом и базы данных с сетевым доступом.
Архитектура СУБД: двухуровневая и трехуровневая.
Централизованные базы данных с сетевым доступом могут иметь двухуровневую или трехуровневую архитектуру.
Двухуровневая система может представлять собой технологию файлового сервера или технологию «клиент-сервер», причем первая технология является частным случаем второй.
Архитектуру «файл-сервер» еще называют технологию удаленного управления данными. Она предполагает выделение одной из машин сети в качестве центральной, которая и будет файловым сервером. На нем хранится база данных, а также файлы, обеспечивающие доступ к данным. Все другие компьютеры сети выполняют функции рабочих станций и являются, строго говоря, клиентами. Данные в соответствии с пользовательским запросом передаются на рабочую станцию блоками. На клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то сервер передает следующую порцию данных. Процесс передачи данных с сервера на клиент продолжается до тех пор, пока не будет выполнен запрос или пока не будут переданы все данные.
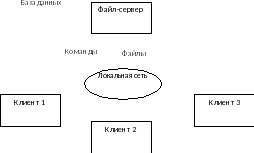
Рис. 3. Технология «файл-сервер»
В качестве примера такой технологии можно привести АБИС «Ирбис 32».
«Клиент-серверная» архитектура – это модель удаленного доступа к данным. Здесь также база данных хранится на сервере. Но СУБД делится на 2 части: клиентскую и серверную. Серверная часть СУБД, т.е. ее ядро находится на сервере, тогда как на клиенте располагаются части приложения, отвечающие за ввод и отображение данных. В основе работы сервера БД лежит использование языка запросов SQL (structured query language). Клиент обращается к серверу БД с SQL-запросами. Сервер же принимает запросы, обрабатывает их и возвращает клиенту только результат обработки. Таким образом, количество передаваемой информации по сети уменьшается во много раз.
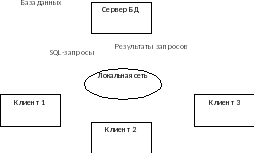
Рис. 4. Технология «клиент-сервер»
Пример «клиент-серверной» модели – АБИС «Ирбис 64».
Трехуровневая модель является расширением двухуровневой модели. В ней вводится промежуточный уровень между клиентом и сервером, который называется сервером приложений. Клиентская часть взаимодействует с пользователем и содержит функции ввода и отображения данных, а также коммуникационные функции, которые обеспечивают доступ клиенту в локальную или глобальную сеть. Это может быть HTML-страница в Web-браузере, либо Windows-приложение, взаимодействующее с Web-сервисами. Сервер баз данных в этой модели только управляет информационными ресурсами БД. Вся программная логика вынесена на сервер приложений, который обеспечивает формирование запросов к базе данных, передаваемых на выполнение серверу баз данных. Сервер приложений может быть Web-сервером или специализированной программой.
Поскольку функции клиента облегчены переносом части прикладных функций на сервер, то он называется «тонким клиентом».
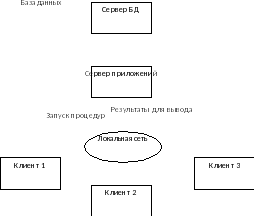
Рис. 5. Трехуровневая архитектура СУБД.
Примером такой модели является АБИС «Opac-Global».
Структурные элементы базы данных: файл, запись, поле. Атрибуты, ключи.
Логическая структура баз данных не зависит от физического представления. Любая база данных состоит из одной или нескольких подбаз, а именно файлов, таблиц, массивов. Каждая такая подбаза включает в себя агрегаты данных, т.е. записи, документы.
Запись (документ) – это совокупность разнотипных и разноструктурных данных, описывающих объект реального мира. Запись состоит из полей.
Поле – это именованный элементарный или составной фрагмент записи (документа), содержащий информацию об определенном аспекте объекта.
Например, база данных, состоящая из таблицы с данными о сотрудниках библиотеки. Запись – это совокупность разнотипных сведений о сотруднике, т.е. его фамилия, имя (строковые данные), дата рождения (тип даты), стаж работы (числовой тип данных), взятые вместе. Поле – это фрагмент записи, например, дата рождения, которая показывает возрастной аспект объекта (сотрудника).
Каждый объект можно охарактеризовать с помощью атрибутов. Атрибуты бывают простыми и составными, однозначными и многозначными.
Простые атрибуты не могут быть разбиты на более мелкие компоненты, т.е. сами являются атомарными. В нашем примере, простые атрибуты – это фамилия, имя, стаж. Составные атрибуты делятся на составляющие. Например, дату рождения можно разбить на год, месяц и число.
Если атрибут отдельного объекта может иметь только одно значение, то его называют однозначным. В нашем примере к таким атрибутам относятся фамилия, имя. Если же атрибут может иметь несколько значений, то его называют многозначным. Например, каждый сотрудник может иметь более одного номера телефона.
Среди атрибутов выделяют такие, с помощью которых можно идентифицировать экземпляр объекта. Такие атрибуты называют ключами. Ключи могут быть простыми и составными. В нашем примере, однозначно идентифицировать сотрудника можно с помощью составного ключа, т.е. фамилии, имени и даты рождения.
Литература.
Голицына, О.Л. Базы данных/ О.Л. Голицына, Н.В. Максимов, И.И. Попов.- Изд. 2-е, испр. и доп.- М.: Форум: Инфра-М, 2007.- 399, [1] с.- (Профессиональное образование)
Малыхина, М. Базы данных: основы, проектирование, использование/ Мария Малыхина.- СПб.: БХВ-Петербург, 2004.- 499, [3] с.
Марков, А.С. Базы данных: введение в теорию и методологию/ А.С. Марков, К.Ю. Лисовский.- М.: Финансы и статистика, 2004.- 510, [2] с.
Понятия предметной области, модели данных. Уровни описания базы данных: внешнее представление, концептуальное представление, внутреннее представление.
Отдельная база данных отражает информацию о некоторой предметной области – наборе объектов, представляющих интерес для пользователей.
Предметная область – это совокупность объектов и понятий, а также связей между ними, сведения о которых обрабатываются и хранятся в базе данных автоматизированной системы.
Реальный мир представляет собой совокупность конкретных и абстрактных понятий, между которыми существуют конкретные связи. Например, книга – конкретное понятие, а интерес к ней читателя – абстрактное понятие. Между этими понятиями существует очевидная связь. Следует отметить, что пользователь, который хочет работать с базой данных, должен владеть основными понятиями, представляющими предметную область.
Представление предметной области в БД реализуется поэтапно:
логическое описание, т.е. данные рассматриваются независимо от особенностей их хранения и поиска в вычислительной среде;
физическое представление, когда учитывается выбранная структура хранения данных.
Представление логической точки зрения называют моделью данных, т.е. это совокупность функциональных характеристик объектов и особенностей представления информации, например, в числовой или текстовой форме. Например, читательский интерес к книге можно выразить в числовой форме (количество выдач за период времени относительно нормы).
Логическое описание предметной области называют концептуальной схемой. Отображение концептуальной схемы на физический уровень называют внутренней схемой. Отражение же взгляда отдельного пользователя на концептуальную схему называют внешней схемой.
Другими словами, одна и та же база данных может иметь различные уровни описания в зависимости от точки зрения:
внешний уровень, на котором пользователи воспринимают данные; здесь отдельные группы пользователей имеют свое представление, свой взгляд на базу данных;
внутренний уровень, на котором операционная система и СУБД воспринимают данные;
концептуальный уровень, на котором происходит отображение внешнего уровня на внутренний и обеспечение независимости этих уровней друг от друга.
Схематично такую трехуровневую архитектуру можно выразить следующим образом:
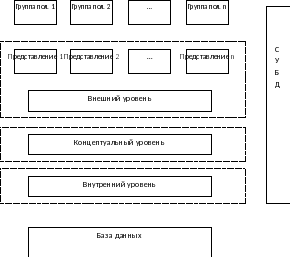
Рис. 1. Трехуровневая архитектура СУБД
Жизненный цикл базы данных.
Как любой программный продукт, база данных имеет собственный жизненный цикл. Главным компонентом в жизненном цикле базы данных является создание единой базы данных и программ, необходимых для ее работы.
Основные этапы жизненного цикла базы данных:
планирование разработки базы данных. Имеется в виду разработка стратегического плана и создание общей информационной модели, которая на последующем этапе может быть проанализирована и изменена. Здесь определяются объем работ, объем ресурсов и стоимость проекта, а также проверяется осуществимость проекта, как технологическая, т.е. оборудование и программное обеспечение, так и операционная, т.е. наличие экспертов и персонала. На этом же этапе решается вопрос экономической целесообразности.
определение требований к системе. Здесь определяется диапазон действий приложения базы данных, состав пользователей и области применения.
сбор и анализ требований пользователей. Проектирование базы данных основано на информации о той части организации, которая будет обслуживаться. Информацию можно получить посредством анкетирования, опроса сотрудников организации, наблюдений за деятельностью организации.
проектирование базы данных. Полный цикл разработки базы данных включает концептуальное, логическое и физическое ее проектирование. Более подробно об этом будет сказано далее.
разработка приложений. Главные составляющие этого процесса – это проектирование транзакций и проектирование пользовательского интерфейса. Транзакции представляют некоторые события реального мира. Все транзакции должны обращаться к базе данных с целью обеспечить соответствие хранимых в ней данных с текущей ситуацией реального мира. Транзакция может состоять из нескольких операций, но с точки зрения пользователя эти операции представляют собой единое целое, переводящее базу данных из одного состояния в другое. Пользовательский интерфейс приложений является одним из важнейших компонентов системы. Интерфейс должен быть удобным и обеспечивать все необходимые функциональные возможности.
реализация. На данном этапе осуществляется физическая реализация базы данных и разработанных приложений, которые позволяют пользователю формулировать запросы к базе данных и манипулировать данными.
загрузка данных. Созданные пустые файлы, предназначенные для хранения информации, заполняются данными.
тестирование. Любой программный продукт должен быть протестирован с целью обнаружения ошибок в прикладных программах и структуре базы данных, а также с целью установления степени надежности и качества. На этом этапе должны использоваться реальные данные, а весь процесс работы должен выполняться строго последовательно с соблюдением методики.
эксплуатация и сопровождение. Данный этап самый продолжительный из всех. Основные действия этапа – это анализ функционирования и поддержка исходной базы данных; модернизация и поддержка вариантов, созданных по запросам пользователя.
Конечное наполнение каждого этапа в значительной степени зависит от сложности разрабатываемого продукта.
Этап проектирования баз данных. Инфологическое проектирование.
Проектирование базы данных – это упорядоченный формализованный процесс создания системы взаимосвязанных описаний, т.е. моделей предметной области, которые связывают хранимые в базе данные с объектами предметной области, которые описываются этими данными. Эти описания нужны для того, чтобы пользователь, не имеющий представления об организации данных в базе, получал в ответ на свой запрос адекватную информацию о состоянии объекта предметной области.
Например, пользователю необходимо создать таблицу статистических данных о составе сотрудников библиотеки, а именно об их образовании. Он не знает, как хранятся данные в базе, с помощью каких ключей идентифицируются записи, не представляет механизмы поиска. Но через дружественный интерфейс прикладной программы пользователь отправляет СУБД запросы с целью получить ответы на вопросы «Сколько сотрудников в библиотеке имеют высшее образование?», «Сколько сотрудников с высшим образованием имеют библиотечное образование?» и т.д. Результаты запроса содержат требуемую адекватную информацию об объектах предметной области в числовом выражении.
Проектирование начинается с анализа предметной области, свойств объектов предметной области, определения информационных потребностей будущих пользователей системы, а также выявления функциональных требований к проектируемой системе. Этим занимается группа людей или один человек – системный аналитик или администратор базы данных. Эта стадия называется концептуальным, или инфологическим, проектированием.
Системный аналитик объединяет отдельные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут понадобиться для решения практических задач. Тем самым формируется обобщенное описание создаваемой базы данных. При создании этого описания используются математические выражения, таблицы, графы и другие средства, понятные всем участникам проектирующей группы. Такое описание, определяющее совокупность информационных объектов, их атрибутов и отношений между ними, динамику изменений предметной области и изменений информационных потребностей пользователей, называется инфологической моделью.
Такая модель является человеко-ориентированной и не зависит от физических параметров среды хранения, будь то память человека или компьютер. Поэтому инфологическая модель не изменяется до тех пор, пока не произойдут какие-либо изменения в реальном мире, требующие внесения изменений в инфологическую модель с целью адекватного отображения предметной области.
ER-модель, модель «сущность-связь».
Инфологическая модель должна отражать составляющие предметной области в достаточном простом, наглядном виде, причем информация должна быть полной и формализованной.
Одним из вариантов такой модели является ER-модель, или модель «сущность-связь» (entity-relationship). При создании ER-модели используются условные обозначения, которые позволяют представить совокупность выполняемых функций и отношения между элементами системы в виде ER-диаграммы.
Существуют приложения, так называемые CASE-продукты, которые поддерживают полный цикл разработки систем баз данных или отдельные его стадии. CASE - Computer Aided Software Engineering. CASE-средства имеют набор инструментов, позволяющих в наглядной форме моделировать предметную область, анализировать эту модель. К ним относятся, например, средства проектирования баз данных ERwin, DataBase Designer.
При построении ER-модели предполагают, что:
та часть реального мира, сведения о которых должны быть помещены в базу данных, может быть представлена как совокупность сущностей;
каждая сущность обладает присущими ей свойствами (атрибутами), характерными для нее и отличающими ее от других сущностей, что позволяет ее идентифицировать;
взаимосвязи объектов могут быть представлены как связи, назначение которых заключается в фиксации взаимозависимости двух или нескольких сущностей.
Как уже упоминалось, ER-моделирование предполагает создание графических диаграмм. Таким образом, каждый тип сущности представляется в виде прямоугольника, содержащего имя сущности; свойства отображаются в виде эллипсов; связь отображается в виде ромба.
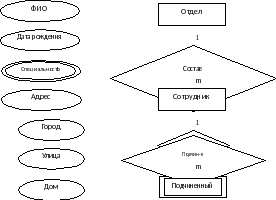
Рис. 2. Пример ER-диаграммы.
Если свойство составное, в примере Адрес, то составляющие его свойства отображаются другими эллипсами.
Если свойство многозначное, то эллипс рисуется двойной линией. Например, сотрудник может иметь несколько специальностей.
Для отображения сущностей слабого (зависимого) типа рисуются прямоугольники с двойными линиями. Соответственно, стороны ромба являются двойными, если это связь сущности слабого типа с сущностью, от которой она зависит.
Тип связи указывается рядом с соответствующей линией, например, «1» или «m».
Инфологическая модель данных «сущность-связь»: сущности и отношения, атрибуты, ключ.
В процессе концептуального проектирования предметная область рассматривается как система, имеющая следующие составляющие:
объект;
средство;
время;
связь.
Объекты обозначают вещи, которые пользователи считают важными в моделируемой части реальности и о которых накапливается информация. Объекты могут быть атомарными или составными. Для составных объектов определяется их внутренняя структура. Каждый объект в конкретный момент времени характеризуется своим состоянием, который определяется с помощью ограниченного набора средств и связей с другими объектами. Время же позволяет моделировать динамические системы. Каждый объект имеет имя и множество экземпляров реального мира. Таким образом, имя объекта – это имя типа, а не конкретного экземпляра. Различают реальные объекты (люди, книги, детали, товары и пр.) и концептуальные объекты (навыки, деловые операции и пр.). Объекты также называют сущностями.
В концептуальной модели могут присутствовать объекты двух типов: сильные и слабые. Сущность является слабой, если ее существование зависит от другой сущности – сильной по отношению к ней. Сильная же сущность наоборот не зависит от существования какого-либо другого объекта. Слабая сущность не сможет присутствовать в модели, если из нее удалить сущность, от которой она зависит. Поскольку в инфологической модели все взаимосвязано, то одна и та же сущность может по отношению к одной сущности являться слабой, а по отношению к другой – сильной.
Каждой сущности присущи свои атрибуты. Если для некоторого экземпляра сущности значение какого-либо атрибута не определено, то этот атрибут будет иметь пустое значение. Например, сотрудник может не иметь ученой степени. Такие атрибуты, которые не являются обязательными для всех экземпляров одной сущности, называются условными.
Атрибуты могут быть простыми и составными. Простые атрибуты не подлежат дальнейшему делению, например, специальность сотрудника. Составные атрибуты можно разделить на простые, например, адрес делится на город, улицу, дом, или дата рождения делится на год, месяц, число.
Кроме того, атрибуты могут быть множественными или единичными, или как еще их называют, многозначными или однозначными. Если атрибут может одновременно иметь несколько значений для одного экземпляра, то это множественный атрибут. Например, специальность – множественный атрибут, а ФИО – единичный.
Также существуют понятия базового и производного атрибутов. Производным считается атрибут, значение которого определяется по значению другого атрибута. Например, атрибут Возраст определяется по значению атрибута Дата рождения, т.е. является производным.
Атрибуты также могут быть статическими и динамическими, т.е. меняться со временем. Например, атрибут ФИО – статический, а атрибут Адрес – динамический.
Из набора атрибутов сущности можно выделить некоторый атрибут, или совокупность атрибутов, как ключевой, если его значение уникально и однозначно идентифицирует сущность, что необходимо в процессе поиска. Если ключ состоит из одного атрибута, его называют простым, иначе составным. Например, в сущности Отдел ключ будет простым и состоит из атрибута Наименование отдела. А в сущности Сотрудник ключ будет составным – ФИО и дата рождения. Здесь мы предполагаем, что в организации может работать полный тезка.
Связи между сущностями еще называют отношением. Например, между сущностями Сотрудник и Проект можно установить связь Участие или Участвует.
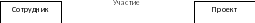
Рис. 3. Диаграмма типа связи Участие
Сама по себе такая структура представляет собой составной объект. Сущности, объединяемые связью, называются участниками. Степень связи определяется количеством участников связи. Если количество участников два, то связь называют бинарной. В большинстве CASE-приложений используются только бинарные связи. Связь между тремя сущностями называется тернарной, между четырьмя – кватернарной, между N объектами – N-арной.
Для характеристики свойств связи также можно использовать атрибуты.
Если каждый экземпляр сущности участвует хотя бы в одном экземпляре связи, то такое участие называют полным, или обязательным; в противном случае – неполным, или необязательным. Например, любой сотрудник состоит в каком-либо отделе, значит, участие сущности является полным.

Рис.4. Диаграмма типа связи Состав
Но не каждый сотрудник участвует в каком-либо проекте. Такое участие будет неполным.
Существует понятие мощности связи, т.е. количество экземпляров сущности, участвующих в связи. Мощность связи выражается показателем кардинальности. Возможны следующие значения показателя кардинальности: «один к одному» (1:1), «один ко многим» (1:m), «многие к одному» (m:1), «многие ко многим» (m:m). Например, если не рассматривать совмещение внутри одной организации, один сотрудник может работать только в одном отделе, и такая связь имеет тип «один ко многим». Но в одном отделе может работать много сотрудников, это связь «многие к одному». Пример связи «многие ко многим»: один сотрудник может участвовать в реализации нескольких проектов, в свою очередь над одним проектом могут работать несколько сотрудников.
Сущность может быть расщеплена на два или более взаимоисключающих подтипов. Тогда сущность, включающая разные подтипы, называют супертипом. А сущность, являющаяся членом супертипа, но выполняющая в нем отдельную роль, называется подтипом. Эти подтипы включают общие атрибуты и связи, которые определяются один раз на более высоком уровне. Также они могут иметь собственные атрибуты и связи. Выделение подтипов может продолжаться на более низких уровнях, на практике достаточным оказывается два-три уровня.
Тип сущности, его подтипы, подтипы этих подтипов образуют иерархию типов сущности.
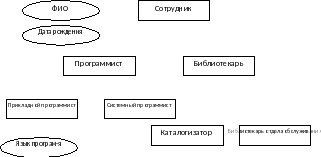
Рис. 5. Пример иерархии типов сущности
Библиотекари обладают всеми свойствами и связями сотрудников, но обратное утверждение неверно. Связь между супертипом и подтипом является связью типа «один к одному».
Физическое проектирование.
Стадия физического проектирования в общем случае включает:
выбор способа организации базы данных;
разработку спецификации внутренней схемы, используя модель данных;
описание отображения концептуальной схемы во внутреннюю.
Многие современные СУБД не предоставляют разработчику какого-либо выбора на этой стадии. Способ хранения базы данных определяется механизмами СУБД автоматически, «по умолчанию» на основе спецификаций концептуальной схемы.
Внешние же схемы базы данных обычно конструируются на стадии разработки приложений.
Литература.
Голицына, О.Л. Базы данных/ О.Л. Голицына, Н.В. Максимов, И.И. Попов.- Изд. 2-е, испр. и доп.- М.: Форум: Инфра-М, 2007.- 399, [1] с.- (Профессиональное образование)
Малыхина, М. Базы данных: основы, проектирование, использование/ Мария Малыхина.- СПб.: БХВ-Петербург, 2004.- 499, [3] с.
Три основных типа моделей данных: иерархическая, сетевая, реляционная.
Обычно различают три модели организации баз данных: иерархические, сетевые и реляционные. Модель в данном случае рассматривается как структура, позволяющая количественно и качественно оценивать логику организации хранения данных и доступа к ним. Например, модель позволяет рассчитать необходимое число шагов при поиске данных. Рассмотрим подробнее каждый тип моделей.
Иерархическая модель данных имеет иерархическую структуру, т.е. каждый элемент связан только с одним стоящим выше элементом, но в то же время на него могут ссылаться один или несколько стоящих ниже элементов. Иерархическая модель изображается в виде графа, называемого деревом. Элементы дерева называются узлами. На самом верхнем уровне имеется только один узел – корень. Узел чаще всего представляет атрибут, описывающий объект. Каждый узел, кроме корня, имеет исходный узел, находящийся на более высоком уровне. Узлы же, связанные на более низком уровне, называются порожденными. Элементы, находящиеся на конце ветви, т.е. не имеющие порожденных, называются листьями.
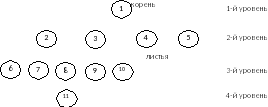
Рис. 6. Пример иерархической структуры
Процедура поиска будет эффективнее, если предварительно установить порядок перехода от одного узла к другому. Выделяют 3 метода обхода: сверху вниз, слева направо, снизу вверх. Таким образом, при обходе дерева будут использоваться указатели на подобные элементы и указатели на порожденные элементы.
При прямом (нисходящем) порядке обхода дерева доступ к любому порожденному узлу всегда начинается с корня с постепенным обходом поддеревьев слева направо и завершением обработки в самых нижних узлах.
Обратный порядок обхода дерева начинается с доступа к самым нижним узлам с постепенным восходящим переходом от одного поддерева к другому слева направо и завершением обработки в корне.
В иерархической модели чаще всего используется прямой порядок обхода дерева, поскольку самые важные данные, как правило, располагаются на самых высоких уровнях, вместе с которыми могут быть извлечены и подчиненные записи.
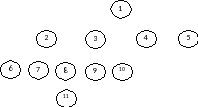
Рис. 7. Пример прямого порядка обхода дерева
При манипулировании данными необходимо помнить, что исключение какого-либо узла из иерархической структуры влечет исключение всех порожденных им узлов, а включение в иерархическую модель какого-либо узла требует наличия для него исходного элемента.
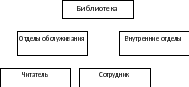
Рис. 8. Пример древовидной структуры
В сетевой структуре любой элемент может быть связан с любым другим элементом. Такую структуру также можно также описать с помощью исходных и порожденных элементов. Эта модель использует ту же терминологию, что и иерархическая, а именно «узел», «уровень», «связь».
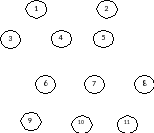
Рис. 9. Пример сетевой структуры
В сетевой модели могут возникнуть рекурсивные связи, когда один экземпляр одного типа взаимодействует с другим экземпляром этого же типа.
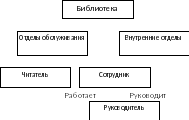
Рис. 10. Пример сетевой модели данных
Сетевые модели обладают тем достоинством, что они могут содержать любые петли. Следовательно, можно отобразить любую концептуальную модель. Недостатком такой модели является сложность реализации.
Реляционная модель данных основана на идее, что любой набор данных можно представить в виде двумерного массива – таблицы. Обычно реляционная модель описывает структуру и взаимоотношения между несколькими различными таблицами. Реляционная модель является удобной. Кроме того, такой способ представления данных понятен пользователю-непрограммисту, а также позволяет легко изменять схему, т.е. присоединять новые элементы данных и записи без изменения подсхем.
Реляционная модель является однородной, т.е. все данные рассматриваются как хранимые в таблицах, где каждая строка имеет один и тот же формат. Каждая строка представляет некоторый объект реального мира или соотношение между объектами.
Отделы
| Код | Название |
| 1 | Отдел абонемента |
| 2 | Отдел периодических изданий |
| 3 | Библиографический отдел |
Сотрудники
| Табельный номер | ФИО | Дата рождения | Стаж в библ.сфере |
| 1 | Иванов И.И. | 01.01.1970 | 8 |
| 2 | Петров П.П. | 02.02.1971 | 1 |
| 3 | Круглов К.К. | 03.03.1983 | 4 |
| 4 | Смирнов С.С. | 04.04.1955 | 20 |
Рис. 11. Пример связанных таблиц в реляционной модели
Реляционная модель данных: отношение, кортеж, поле, ключи, кардинальность, степень.
Основоположником теории реляционных баз данных является британский математик Эдгар Франк Кодд, разработавший ее в 70-х годах, будучи в то время сотрудником фирмы IBM.
Название «реляционная база данных» произошло от английского слова «relation», что означает «отношение» - в математике особая форма таблиц.
Основными понятиями, определяющими реляционную модель, являются отношение, кортеж, атрибут, кардинальность, степень, ключи.
Отношение (таблица базы данных) – это двумерный массив, содержащий информацию об одном классе объектов. Например, отношение Отделы содержит информацию об отделах.
Таблица состоит из полей, записей и ячеек.
Поле (атрибут) содержит значения одного из признаков, характеризующих объекты. Число полей равно числу признаков, характеризующих объекты. Например, в таблице Сотрудники имеется 3 атрибута.
В ячейке хранится конкретное значение соответствующего поля.
Запись – это строка таблицы. Она отражает совокупность значений всех признаков, описывающих объект. Число записей соответствует числу объектов одного типа, данные о которых содержатся в таблице.
В теории баз данных термину «запись» соответствует понятие «кортеж» - последовательность атрибутов, связанных между собой отношением «И».
Количество строк в таблице определяет значение кардинальности отношения, а количество полей – степень отношения. Например, для таблицы Сотрудники степень отношения равна четырем, а кардинальность – трем.
Одним из важных понятий, используемых для построения оптимальной структуры реляционной базы данных, является понятие ключа, или ключевого поля.
Первичный ключ – это поле или подмножество полей, которые уникально, т.е. единственным образом определяют строки. Первичный ключ, который включает более одного поля, называют множественным, или составным. Первичный ключ не может быть полностью или частично пустым.
Остальные ключи, которые также можно использовать в качестве первичных, называют альтернативными ключами.
Например, в таблице Сотрудники первичным ключом будет поле Табельный номер. Однако сотрудника однозначно можно также идентифицировать с помощью составного ключа ФИО+Дата рождения, этот ключ будет являться альтернативным.
В случае использования составного первичного ключа должно выполняться 2 условия:
условие уникальности, которое означает, что в любой момент времени таблица базы данных не может содержать никакие две различные записи, имеющие одинаковые значения ключевых полей. Выполнение условия уникальности является обязательным.
условие минимальности – означает, что ни одно из входящих в ключ полей не может быть исключено из него без нарушения уникальности.
Ограничительные условия. Правило категорной целостности. Правило целостности на уровне ссылок.
База данных должна поддерживаться в целостном непротиворечивом состоянии. Именно такое состояние базы данных гарантирует корректность данных. Поддержка целостности базы данных реализуется посредством ограничений, накладываемых на данные. Ограничения можно разделить на 2 типа: ограничение домена и корпоративные ограничения целостности.
Домен – это множество допустимых для атрибута значений. Например, для атрибута Табельный номер в таблице Сотрудники множество допустимых значений – (0; +∞), так же как и для атрибута Стаж в библ.сфере. Однако значения этих доменов не являются сравнимыми, хотя оба относятся к типу целых чисел.
Ограничение домена заключается в том, что каждый атрибут определяется на своем домене, или наоборот, домен атрибута задает множество значений, которые может принимать атрибут.
Если значение атрибута в настоящий момент неизвестно для данного кортежа, то в этом случае рекомендуется использовать понятие NULL. NULL – это не значение атрибута, а обозначение отсутствия какого-либо значения. Например, новый сотрудник принят в библиотеку, но его стаж в библиотечной сфере еще точно не подсчитан.
Корпоративные ограничения накладываются на информацию в таблицах согласно правилам, которые существуют в данной организации. Эти правила еще называют дополнительными правилами поддержки целостности, определенные пользователем или администратором баз данных. Например, рабочее расписание отдела должно формироваться с учетом двухсменного графика.
Рассмотрим два важных понятия, связанных с поддержкой целостности баз данных – это категорная целостность и целостность на уровне ссылок.
Категорная целостность означает, что кортеж не может записываться в базу данных до тех пор, пока значения всех его ключевых атрибутов не будут полностью определены. Другими словами, никакой ключевой атрибут любого кортежа не может содержать отсутствующего значения, обозначающего определителем NULL. Если один из атрибутов ключа не определен, то происходит нарушение уникальности, т.е. он перестает быть идентифицирующим атрибутом.
При построении отношений для связывания строк одной таблицы со строками другой таблицы используются так называемые внешние ключи – набор атрибутов одного отношения, являющийся возможным ключом для другого. Внешний ключ таблицы является ссылкой на первичный ключ другой таблицы. База данных, в которой все непустые внешние ключи ссылаются на текущие значения ключей другого отношения, обладает целостностью на уровне ссылок. Отсюда вытекает, что внешние ключи также не должны содержать значения NULL. Например, при удалении записи о каком-либо отделе из таблицы Отделы в таблице Сотрудники появятся записи, не связанные ни с одним отделом. В таком случае произойдет нарушение целостности базы данных.
Литература.
Голицына, О.Л. Базы данных/ О.Л. Голицына, Н.В. Максимов, И.И. Попов.- Изд. 2-е, испр. и доп.- М.: Форум: Инфра-М, 2007.- 399, [1] с.- (Профессиональное образование)
Малыхина, М. Базы данных: основы, проектирование, использование/ Мария Малыхина.- СПб.: БХВ-Петербург, 2004.- 499, [3] с.
Фуфаев, Э.В. Базы данных: учебное пособие для студентов образовательных учреждений среднего профессионального образования/ Э.В. Фуфаев, Д.Э. Фуфаев.- 3-е изд., стер.- М.: Академия, 2007.- 319, [1] с.- (Среднее профессиональное образование)
Тема 3. Проектирование реляционных баз данных.
Универсальное отношение. Избыточность данных. Функциональные зависимости. Нормализация. Нормальные формы.
Существует 2 подхода к проектированию реляционной базы данных. Первый подход, традиционный, был предложен Коддом. Он предполагает создание на этапе концептуального проектирования не концептуальной модели данных, а непосредственно реляционной схемы, состоящей из определений реляционных отношений.
Второй подход основан на концептуальной модели данных, которая создается на этапе концептуального проектирования. Затем эта модель преобразуется в реляционную.
При первом подходе используются методы нормализации таблиц. Нормализация представляет собой способы разделения одной таблицы базы данных на несколько таблиц, или пошаговый процесс замены одной совокупности отношений другой, где отношения имеют более простую и регулярную структуру.
Например, стоит задача распределения сотрудников библиотеки по проектам, находящимся в реализации. В распоряжении имеется сводная таблица:
| Отдел | Сотрудник | Должность | Проект | Руководитель проекта | Время, затрачиваемое на проект, % |
| Отдел автоматизации | Иванов И.И. | Программист | Проект 1 | Петров П.П. | 30 |
| Проект 2 | Краснов К.К. | 30 | |||
| Петров П.П. | Системный администратор | Проект 1 | Петров П.П. | 25 | |
| Проект 2 | Краснов К.К. | 15 | |||
| Проект 3 | Белов Б.Б. | 40 | |||
| Научно-методический отдел | Печкин П.П. | Методист | Проект 2 | Краснов К.К. | 60 |
| Лавочкин Л.Л. | Методист | Проект 2 | Краснов К.К. | 20 | |
| Проект 3 | Белов Б.Б. | 50 |
Эта таблица не является отношением, т.к. имеет множественные столбцы. Атомарным является только столбец Отдел. Преобразуем сводную таблицу в отношение следующим образом:
| Отдел | Сотрудник | Должность | Проект | Руководитель проекта | Время, затрачиваемое на проект, % |
| Отдел автоматизации | Иванов И.И. | Программист | Проект 1 | Петров П.П. | 30 |
| Отдел автоматизации | Иванов И.И. | Программист | Проект 2 | Краснов К.К. | 30 |
| Отдел автоматизации | Петров П.П. | Системный администратор | Проект 1 | Петров П.П. | 25 |
| Отдел автоматизации | Петров П.П. | Системный администратор | Проект 2 | Краснов К.К. | 15 |
| Отдел автоматизации | Петров П.П. | Системный администратор | Проект 3 | Белов Б.Б. | 40 |
| Научно-методический отдел | Печкин П.П. | Методист | Проект 2 | Краснов К.К. | 60 |
| Научно-методический отдел | Лавочкин Л.Л. | Методист | Проект 2 | Краснов К.К. | 20 |
| Научно-методический отдел | Лавочкин Л.Л. | Методист | Проект 3 | Белов Б.Б. | 50 |
Таким образом, в первую очередь получается универсальное отношение, куда включаются все атрибуты. Т.е. универсальное отношение может использоваться в качестве отправной точки.
Однако при использовании универсального отношения возникает проблема избыточности данных, т.е. значения столбцов многократно повторяются, происходит дублирование. Полностью от дублирования данных отказаться нельзя, но оно должно быть в несколько другом виде, иначе нарушится целостность базы данных. Избыточность нужно минимизировать, чтобы сократить объем памяти, необходимый для физического хранения данных.
Для устранения избыточности данные нужно разбить на разные таблицы, т.е. нормализовать базу данных.
При описании нормальных форм используется понятие функциональной зависимости, что является связью типа «многие к одному» между множествами атрибутов. Другими словами, атрибут B функционально зависит от атрибута A (A-B), если каждое отдельное значение атрибута A связано только с одним значением атрибута B. Обратное утверждение неверно, т.е. одно и то же значение атрибута B может соответствовать разным значениям атрибута A.
Например, в нашем отношении Проекты существует функциональная зависимость Сотрудник-Должность. Т.е. сотрудник имеет одну должность (Печкин-Методист), но эту должность могут иметь и другие сотрудники (Печкин – методист, и Лавочкин - методист).
Функциональная зависимость A-B называется полной, если удаление какого-либо атрибута из группы A приводит к потере зависимости.
Функциональная зависимость A-B называется частичной, если в группе атрибутов A есть один или несколько атрибутов, при удалении которых эта зависимость сохраняется.
Например, атрибут Время связан полной функциональной зависимостью с группой атрибутов Сотрудник+Проект.
Многозначная зависимость выражается следующим образом. Один атрибут таблицы многозначно определяет другой атрибут той же таблицы, если для каждого значения первого атрибута существует хорошо определенное множество значений второго атрибута.
Например, в таблице Проекты существует многозначная зависимость Проект-Сотрудник, т.е. над проектом работают утвержденные приказом сотрудники. Для Проекта 1 хорошо определенным множеством будет множество значений (Иванов И.И., Петров П.П).
Всего существует 6 форм нормализации:
первая нормальная форма (1НФ);
вторая нормальная форма (2НФ);
третья нормальная форма (3НФ);
нормальная форма Бойса-Кодда (НБКФ);
четвертая нормальная форма (4НФ);
пятая нормальная форма (5НФ).
Для реляционных баз данных необходимо, чтобы все отношения базы данных обязательно находились в 1НФ. Нормальные формы более высокого порядка могут использоваться разработчиками по своему усмотрению, но грамотный специалист стремится довести нормализацию до 3 уровня.
Таблица находится в первой нормальной форме тогда и только тогда, когда она не содержит одинаковых строк и все ее атрибуты имеют атомарные значения. Реляционная таблица, находящаяся в 1НФ, имеет первичный ключ. Таким образом, сводная таблица Проекты не находится в 1НФ.
Таблица находится во второй нормальной форме, если она удовлетворяет определению 1НФ и все ее атрибуты, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Универсальное отношение Проекты находится в 1НФ, но не находится во 2НФ. Таблица имеет составной первичный ключ Сотрудник+Проект, а также множество неключевых атрибутов, зависящих только от какой-либо части первичного ключа. Так, атрибуты Должность и Отдел зависят от атрибута Сотрудник, а атрибут Руководитель проекта зависит от атрибута Проект. Следовательно, эти атрибуты не связаны с первичным ключом полной функциональной зависимостью и из исходной таблицы их можно удалить, выделив их в две другие таблицы. Приведем базу данных к 2НФ.
Таблица Сотрудники.
| Сотрудник | Отдел | Должность |
| Иванов И.И. | Отдел автоматизации | Программист |
| Петров П.П. | Отдел автоматизации | Системный администратор |
| Печкин П.П. | Научно-методический отдел | Методист |
| Лавочкин Л.Л. | Научно-методический отдел | Методист |
Таблица Проекты
| Проект | Руководитель проекта |
| Проект 1 | Петров П.П. |
| Проект 2 | Краснов К.К. |
| Проект 3 | Белов Б.Б. |
Таблица Занятость в проектах.
| Сотрудник | Проект | Время, затрачиваемое на проект, % |
| Иванов И.И. | Проект 1 | 30 |
| Иванов И.И. | Проект 2 | 30 |
| Петров П.П. | Проект 1 | 25 |
| Петров П.П. | Проект 2 | 15 |
| Петров П.П. | Проект 3 | 40 |
| Печкин П.П. | Проект 2 | 60 |
| Лавочкин Л.Л. | Проект 2 | 20 |
| Лавочкин Л.Л. | Проект 3 | 50 |
Таблица находится в третьей нормальной форме, если она удовлетворяет определению 2НФ и ни один из ее неключевых атрибутов не связан функциональной зависимостью с любым другим неключевым атрибутом.
Все наши таблицы находятся в 3НФ. Но если предположить, что в каждом отделе есть только свои уникальные должности, то таблица Сотрудники не удовлетворяла бы определению и подлежала бы разбиению на 2 таблицы (Сотрудник+Должность и Должность+Отдел). Но должность «библиотекарь» не в одном отделе библиотеки.
Таблица находится в нормальной форме Бойса-Кодда тогда и только тогда, когда любая функциональная зависимость между ее атрибутами сводится к полной функциональной зависимости от возможного первичного ключа.
Часто случается на практике, что 3НФ совпадает с НФБК. Но таблицу требуется привести к НФБК, если выполняются следующие условия:
отношение имеет более одного потенциального ключа;
два потенциальных ключа являются составными;
два потенциальных ключа перекрываются, т.е. имеют хотя бы один общий атрибут.
Полная декомпозиция отношения – это совокупность его проекций, соединение которых полностью эквивалентно исходному отношению. Проекция – это копия таблицы, включающая не весь набор атрибутов.
Таким образом, исходная таблица претерпела полную декомпозицию. Однако полученная совокупность таблиц может быть улучшена путем введения дополнительных таблиц (справочников).
В четвертой и пятой нормальных формах учитываются многозначные функциональные зависимости. При чем 4НФ является частным случаем 5НФ.
Таблица находится в пятой нормальной форме тогда и только тогда, когда в каждой ее полной декомпозиции все проекции содержат возможный ключ.
Четвертая нормальная форма означает, что полная декомпозиция должна быть соединением ровно двух проекций.
Как отмечалось, оптимизация таблиц базы данных заканчивается 3НФ.
Преобразование модели «сущность-связь» в реляционную.
Вспомним, что концептуальная модель данных состоит из ряда компонентов: сущностей, связей, атрибутов.
Поставим задачу распределения сотрудников библиотеки по проектам.
Наша предметная область – это взаимодействие двух сущностей: Сотрудник и Проект.
Сотрудник характеризуется следующими свойствами: фамилия, имя, отчество, должность, отдел. Для однозначной идентификации сотрудника будем использовать табельный номер, чтобы исключить наличие полных тезок. Причем атрибуты Должность и Отдел не используются для решения поставленной задачи, они служат для реализации сервисных функций, например, формирования статистики по отделам и пр.
Проект характеризуется названием и руководителем проекта.
Взаимодействие сущностей Сотрудник и Проект реализуется связью Распределение рабочего времени. Мощность связи – «многие ко многим». Для идентификации связи отдельных экземпляров сущностей необходимо наличие у связи дополнительных свойств: время, затрачиваемое на проект, в процентном соотношении к общему рабочему времени.
Составим ER-диаграмму нашей задачи.
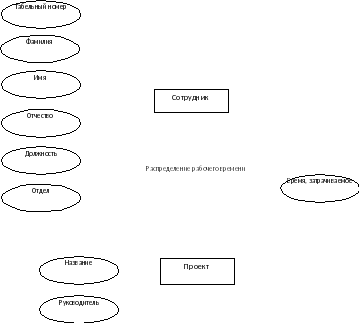

Рис. 1. ER-диаграмма рассматриваемой задачи
Эта диаграмма находится в третьей нормальной форме, т.к. сущности не имеют повторяющихся свойств, неключевые свойства зависят от ключевых свойств, причем зависимость полная, а также неключевые свойства не являются взаимозависимыми.
Далее ER-диаграмму нужно преобразовать в реляционную модель. Первый шаг состоит в превращении каждой сущности в отдельную таблицу. Связь типа «многие ко многим» также выделяют в отдельную таблицу. Каждое свойство становится атрибутом – столбцом соответствующей таблицы. В результате этих действий получим реляционную схему данных, представленную ниже. Преобразуем связи во внешние ключи. Связь Распределение рабочего времени предполагает добавление ID Проект в таблицу Проекты.
Сотрудники
| ID Сотрудник |
| Фамилия |
| Имя |
| Отчество |
| Должность |
| Отдел |
Проекты
| ID Проект |
| Название |
| Руководитель |
Распределение рабочего времени
| ID Сотрудник |
| ID Проект |
| Время, затрачиваемое |
Рис. 2. Реляционная схема рассматриваемой задачи
Все таблицы находятся в первой нормальной форме, т.к. каждый столбец каждой таблицы неделим и нет столбцов с одинаковыми по смыслу значения в одной таблице. Таблицы имеют первичные ключи, которые однозначно определяют строки и неизбыточны, следовательно, таблицы находятся во второй нормальной форме.
В таблице Проекты имеется атрибут Руководитель, значения которого может совпадать для нескольких строк, т.е. один и тот же человек может руководить работой не одного проекта. Следовательно, хранение фамилии руководителя в таблице Проекты будет избыточным. Кроме того, существует вероятность допущения ошибок в различных строках при вводе одной и той же фамилии. Чтобы предотвратить это, сделаем декомпозицию отношения Проекты, в результате чего получим еще одну таблицу Руководители проектов. То же самое сделаем для атрибутов Должность и Отделы в таблице Сотрудники.
Сотрудники
| ID Сотрудник |
| Фамилия |
| Имя |
| Отчество |
| ID Должность |
| ID Отдел |
Проекты
| ID Проект |
| Название |
| ID Руководитель |
Распределение рабочего времени
| ID Сотрудник |
| ID Проект |
| Время, затрачиваемое |
Должности
| ID Должность |
| Название |
Отделы
| ID Отдел |
| Название |
Руководители
| ID Руководитель |
| Фамилия |
| Имя |
| Отчество |
Рис. 3. Структура базы данных Проектные работы
Все таблицы находятся в третьей нормальной форме.
Литература.
Голицына, О.Л. Базы данных/ О.Л. Голицына, Н.В. Максимов, И.И. Попов.- Изд. 2-е, испр. и доп.- М.: Форум: Инфра-М, 2007.- 399, [1] с.- (Профессиональное образование)
Малыхина, М. Базы данных: основы, проектирование, использование/ Мария Малыхина.- СПб.: БХВ-Петербург, 2004.- 499, [3] с.
21








Похожие файлы
Полезное для учителя




Распродажа видеоуроков!

1730 руб.
2660 руб.

1600 руб.
2460 руб.

1770 руб.
2720 руб.

1900 руб.
2930 руб.
ПОЛУЧИТЕ СВИДЕТЕЛЬСТВО МГНОВЕННО

* Свидетельство о публикации выдается БЕСПЛАТНО, СРАЗУ же после добавления Вами Вашей работы на сайт
Удобный поиск материалов для учителей
Проверка свидетельства